고정 헤더 영역
상세 컨텐츠
본문 제목
[Paper Review] A Simple Framework for Contrastive Learning of Visual Representation( SimCLR )
본문
반응형
이번에 리뷰할 논문은 A Simple Framework for Contrastive Learning of Visual Representation 입니다. Contrastive Learning을 visual representation에 접목한 논문입니다.
KAIST에서 제안한 CSI를 읽으려는데 contrastive learning에 대한 이해가 부족해 미리 리뷰해 보았습니다.
Abstract
- visual representation의 contrastive learning을 위한 framework인 SimCLR을 제안했다고 합니다.
- data augmentation의 구성이 분류 문제에 중요한 역할을 한다는 점과,
- contrastive loss와 학습 가능한 선형 변환은 성능을 크게 높인다는 점,
- contrastive learning은 larger batch-size, training-step 에 supervised learning 에 비해 더 큰 이득을 본다는 점
- 을 종합해 보니 SimCLR 이 좋은 성능을 냈다고 합니다.
1. Introduction
- human supervision(인위적으로 부여된 label) 없이 visual representation을 학습하는 것은 오래동안 풀리지 않은 문제였다고 합니다.
- 대부분의 접근법은 generative, discrminative 한 방식으로 나뉘는데
- 전자는 pixel 단위로 접근해야 하기 때문에 그 비용이 너무 컸고,
- 후자는 인간의 pretext가 필요했다고 합니다.
- contrastive learning에 기초한 discrminative 모델을 사용해 sota를 갱신했다고 합니다. 이는 특별한 모델의 구조를 요구하지도, 많은 양의 메모리를 요구하지도 않았다고 합니다.
Contrastive Learning은 아래와 같은 성질을 보였다고 합니다.
- stronger augmenation이 supervised learning 에 비해 더 좋은 성능 향상을 보였고
- contrastive loss, cross entropy는 normalized embedding, tempreature scaling에도 영향을 받으며
- representation과 contrastive learning 사이의 비선형 변환 도입 시 representation 성능이 좋아지고
- 더 큰 batch size와 longer training 에 의해 supervised learning 에 비해 더 큰 성능 향상을 보였다고 합니다.
이런 것들을 조합해보니 역시나 SimCLR이 짱이었다.. 합니다. 자랑이 많네요 ㅎㅎ
2. Method
2.1 The Contrastive Learning Framework
Concept
SimCLR learns representations by maximizing agreement between differently augmented views of the same data example via s contrastive loss in the latent space.
- 가장 중요한 문장인 것 같아 해석해보면, 하나의 sample에 대해 augmentation t, t'을 각각 적용해 얻은 representation 간의 agreement를 최대화 시키는 방향으로 모델이 학습된다고 합니다.

- 하나의 data sample x에 두 개의 augmentation t ~ T, t' ~ T 를 각각 적용한 뒤
- NN base Encoder f($\cdot$) 를 적용하여 얻은 representation vector $h_{i}, h_{j}$를 각각 얻고
- hidden layer $g(c\dot)$를 적용해 representation $z_{i}, z_{j}$ 를 각각 얻습니다.
- 이 때 $x_{j}$ 와 $k \neq j$ 인 $k$ 에 대해$x_{k}$ 에서 얻은 representation 의 class를 일치하게끔 학습시키는 것이 목표입니다.
Loss Function

- N 개의 데이터를 random sample 하여 mini-batch를 이루고 i 번째 sample에 대해 2(N - 1) 개의 augmented sample로 negative sample을 구성합니다. 별도로 negative sample을 만들어주지 않습니다.
- $sim(u, v) = u^{T}v/||u||||v||$(이 때, $u, v$는 $l_{2}$ normalized vector)은 cosine similarity를 의미합니다.
- 위의 식에서 로그 안의 항을 분리해주면 , 분모의 식은 positive sample 간의 유사도 $\cdots (1)$, 분모의 식은 나머지 negative sample 과의 유사도의 합 $\cdots (2)$ 를 의미합니다.
- 즉 loss function은 , positive sample 간의 유사도는 크게, negative sample 간의 유사도는 작게 해주는 효과가 생깁니다.
2.2 Training with Large Batch Size
- 큰 batch size로 학습시킬 때 contrastive framework SimCLR 이 좋은 성능을 보였다고 합니다.
- 그런데, 큰 batch size를 사용하면 SGD, Momentum에서 불안정한 성능이 발생하게 되는데, 이를 방지하기 위해 LARS 라는 optimizer를 사용했다고 합니다.
- 카카오브레인 테크 블로그에 정리된 내용을 첨부하니, 참고하시면 좋을 듯 합니다!
2.3 Evaluation Protocol
- 논문 재현에 필요한 자세한 환경이 서술돼있습니다.
3. Data Augmentation for Contrastive Representation Learning
- 기존의 contrastive learning은 모델의 구조를 바꿔 사용했는데, 이런 복잡한 문제를 random cropping 으로 해결할 수 있는 것을 발견했다고 합니다.
3.1 Composition of data augmentation operations is crucial for learning good representation
- image data augementation 에는 두 가지의 종류가 있습니다.
- spatial/geometric transformation -> cropping, resizing, roataion, cutout
- appearance transformation -> color distortion(color dropping, brightness, contrast, saturation, hue), Gaussian Blur, Sobel Filtering

- augmentation 기법들의 예시입니다.

- 두 개의 augmetnation을 작용했을 때 ImageNet에서 top1 accuracy를 낸 결과입니다.
- 한 개의 augmentation만 적용했을 때 더 좋은 결과를 내는 경우는 없었다고 합니다.
- feature generalization 을 위해서는 crop + color distortion 조합이 가장 좋았다고 합니다.
3.2 Contrastive Learning needs stronger data augmentation than supervised learning
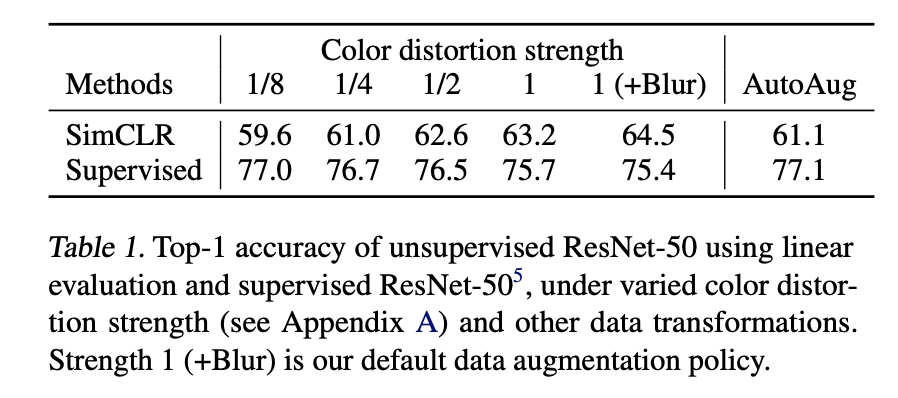
- strong augmentation이라고 모두 성능을 좋게하는 것이 아닌, strong color distortion에 의해 성능이 개선되는 경향이 보였다고 합니다.
4. Architectures for Encoder and Head
4.1 Unsupervised Contrastive Learning benefits (more) from Bigger models
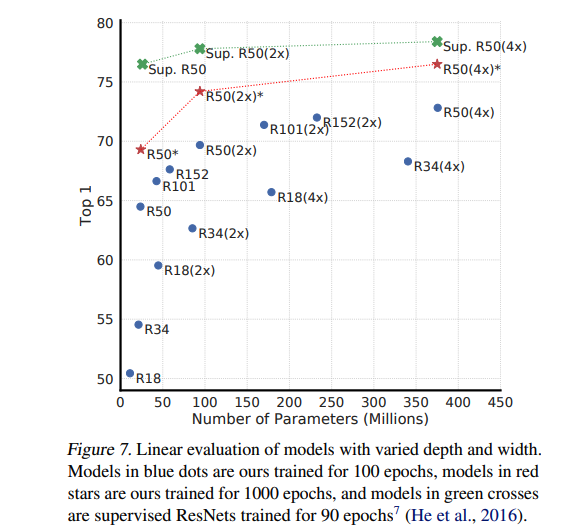
- 모델의 사이즈가 커질수록 supervised learning에 근접한 결과를 낸다고 합니다.
4.2 A non-linear projection head improves the representation quality of the layer before it
- 위 그림에서 변환 $g(\cdot)$는 선형 변환보다는 비선형 변환일 때 더 성능이 좋았다고 합니다.
5. Loss Function and Batch Size
5.1 Normalized corss entropy loss with adjustable temperature works better than alternatives

- Loss function으로는 NT-Xent가 가장 좋은 성능을 보였다고 합니다.
5.2 Contrastive Learning benefits (more) from larger batch sizes and longer training
- training step 이 늘어날수록 batch size에 의한 차이가 줄어들었다고 합니다.
- supervised learning과는 다르게 더 큰 batch size는 더 많은 negative sample을 제공하고, 이로 인해 더 빠른 수렴을 가능하게 했다고 합니다.
6. Comparison with State-of-the-art

- SimCLR이 짱이라고 하네요.
정리
- 기존의 supervised classification 기법들은 고양이 사진과 고양이 라벨, 개 사진과 개 라벨을 주어 "자 이게 고양이고, 이게 개야!" 하고 학습시키게 했습니다.
- contrastive learning 기법은 고양이 사진과 고양이 라벨을 주고, 개와 원숭이 사진을 주며 "이건 고양인데, 쟤넨 고양이 아니야!" 하고 같은 라벨을 가지는 데이터끼리는 유사한 특성을, 다른 라벨을 가지는 데이터 간에는 다른 특성을 가지는 representation을 만들게끔 모델을 학습시키는 방법입니다.
- 이 때, 고양이와 원숭이에 해당하는 데이터를 줄 때 augmentation을 주어 negative sample을 늘리고, augmentation을 준 data를 postiive sample로 주었다고 합니다.
- 이 때, supervised learning과는 다르게 큰 batch size, 많은 training step이 좋은 성능을 내는 데에 도움을 주었고, 안정적인 학습을 위해 기존에 자주 사용되던 optimizer가 아닌 LARS를 사용했다고 합니다.
참고 자료
- 카카오브레인 테크 블로그 - 링크
'ML, DL > Paper Review' 카테고리의 다른 글
| [Paper Review] Densely Connected Convolutional Networks (1) | 2021.07.20 |
|---|





댓글 영역