고정 헤더 영역
상세 컨텐츠
본문
반응형
01. 머신러닝 파이프라인의 필요성
포드에서는 공정을 정형화하고, 자동화해 비용과 시간을 절약했다고 합니다.
과연 그 이점이 이것 뿐이었을까요? 파이프라인을 잘 구성해두었을 때 얻는 이점에 대해 알아보고, 이것이 왜 필요한지 고개를 끄덕일 수 있는 과정을 함께 알아보도록 하겠습니다.
파이프라인을 잘 구성했을 때 얻는 이점
01. 생산력 향상
사용자에게 손으로 쓴 숫자의 이미지를 서버에 request 받아, MNIST 모델로 숫자를 분류해 response를 주는 작업을 한다고 생각해봅시다. 이 파이프라인이 분류되지 않고, 모든 코드가 한 군데에 이어져있다면?
"아! 이게 어디서 터진 에러지? 입력단? 모델? 출력단?"
하는 고민에 빠지게 되겠죠.
하지만 이를 잘 나누어 놨다면, 어디서 에러가 났는지, 어떤 부분에서 시간을 많이 먹는지 쉽게 파악이 가능할테니 유지 보수에 유리하고, 이는 곧 생산력의 향상으로 이어집니다.
또, 모델이 한 개라면 언급한 과정이 그리 번거롭지만은 않을 것입니다. 하지만 모델이 수 십개라면? 수 백개라면? 이를 하나하나 뜯어서 유지보수하는 것은 너무 많은 자원을 소모합니다.
02. 예측 가능한 품질
offline 데이터로 학습된 모델의 성능은 날이 갈수록 떨어지게 돼있습니다.
모델이 하루가 지나면 성능이 얼마나 떨어지나요? 일주일은 어떤가요? 한 분기는 어떤가요? 이 정보는 모니터링의 우선순위를 판단하는 데 도움이 됩니다. 하루 동안 모델을 업데이트하지 않으면 제품의 품질이 심각하게 저하되는 경우 모델을 지속적으로 모니터링하는 엔지니어를 두는 것이 좋습니다. 대부분의 광고 게재 시스템에는 매일같이 새로운 광고가 유입되므로 업데이트가 매일 이루어져야 합니다. 예를 들어
Google Play 검색
의 머신러닝 모델이 업데이트되지 않으면 1개월 이내에 부정적인 영향을 미칠 수 있습니다.
Google+
의 HOT 소식에서 게시물 식별자를 갖지 않는 일부 모델은 자주 내보낼 필요가 없습니다. 게시물 식별자를 갖는 다른 모델은 훨씬 더 자주 업데이트됩니다. 또한 갱신 기준은 시간에 따라 변화할 수 있습니다. 특히 모델에서 특성 열이 추가 또는 삭제될 때 그러합니다.
출처 : 구글 머신러닝의 규칙 - 링크
주의! 뇌피셜입니다. 혹은 이렇게도 생각합니다. 사용자들의 입력을 큰 랜덤변수라고 생각해보면, 시간이 지나고 서비스의 사용량이 증가하면서 당연히 평균(정상치)에서 벗어나는 입력이 많아질 것이고, 이는 자연스레 모델의 성능 저하를 야기할 것입니다. 이러한 이상치의 데이터를 거르고, 합당한 입력이라면 이를 포함해 다시 학습시킨다면 모델의 성능을 유지할 수 있을 것입니다.
03. 장애 대응 능력
파이프라인을 나누어두지 않고 end-to-end 로 구성하여 서비스를 제공하고 있다면 문제가 어디서 생겼을지 모를 확률이 매우 높습니다. 서버단에서 문제가 생긴 건지, 모델의 가중치에 문제가 생겨 쓰레기값을 뱉고 있는 건지 구분을 못 할 수 있죠. 이를 잘 나누어둔다면 어디서 문제가 생겼는지 쉽게 파악할 수 있고, 에러에 더욱 쉽게 대응할 수 있게 됩니다.
기술 부채
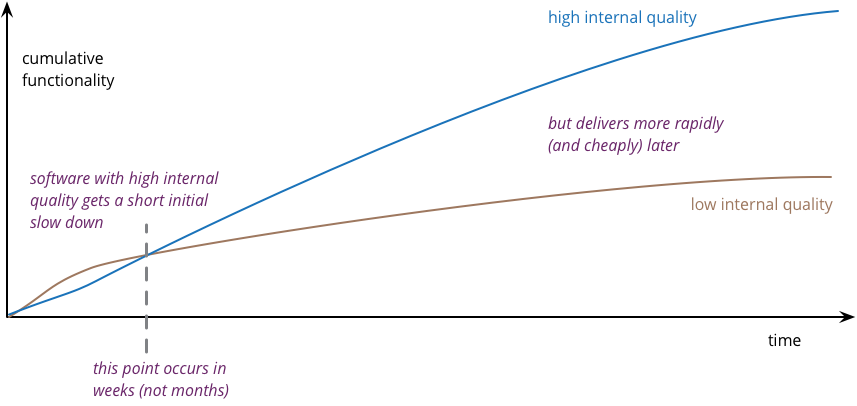
출처 : Is High Quality Software Worth the Cost? - 링크
기술 부채란 "우선 되게만 해!" 하고 큰 고민 없이 기술을 구현해두었을 때 추후 치뤄야 할 빚을 말합니다. 모델을 수동으로 배포해야만 하거나, 데이터를 손수 합쳐줘야 한다거나 하는 경우 기술 부채가 발생합니다.
사실 학습시킨 모델의 가중치를 뽑아 배포하는 것은 어렵지 않습니다.
# save model
torch.save(model.state_dict(), 'path_to_weight_file.pth')
# load model
model = Model()
model.load_state_dict(torch.load('path_to_weight_file.pth'))
model.eval()학습된 모델의 가중치 파일만 있으면 세 줄의 코드만으로 모델을 배포할 수 있게 됩니다.
하지만 새로 모델을 학습시킬 때마다
"ㅇㅇ님 가중치 파일 보내드렸습니다 갱신해주세요~"
할 순 없는 노릇입니다.
ML 모델의 개발, 배포는 어렵지 않지만 이를 감싸는 시스템이 돌아가는 과정을 유지 보수하는 과정은 매우 많은 비용을 필요로 합니다.
모델의 배포를 자동화시키는 것 외에도 기술 부채를 줄일 여지는 무척 많습니다.
단위 테스트를 만들어 에러가 생길 여지를 줄인다거나, 꾸준한 리팩토링으로 그 성능을 향상시킨다거나, restAPI를 잘 구성해두어 어디서든 그 값을 가져올 수 있게 한다거나 하는 방법들이 있을 것입니다.
하지만 아쉬운 점은 기존에 개발자들이 마주하던 문제와 ML 시스템에서 마주하는 문제가 아주 미묘하게 다르단 것입니다.
단위 테스트를 구성하는 단위를 나누기도 무척 애매합니다. 또, 일부만을 고치기가 쉬운 일이 아닙니다.
그렇다면 어떻게 ML 시스템을 유지하는 데에 발생하는 기술 부채를 줄일 수 있을까요?
그 전에 다음 포스팅에서는 ML 시스템을 구성할 때 발생하는 문제의 특성을 알아보겠습니다.
출처 : 인프런 머신러닝 엔지니어 실무 - 링크
많이 부족합니다! 비난 없는 태글과 댓글은 언제나 환영합니다.
'MLOps' 카테고리의 다른 글
| [내가 한 거 기록하는 Docker]03. Dockerfile (0) | 2021.07.27 |
|---|---|
| [내가 한 거 기록하는 Docker]02. 도커 이미지와 docker hub? (0) | 2021.07.24 |
| [내가 한 거 기록하는 Docker]01. 도커 설치 (0) | 2021.07.23 |
| [머신러닝 엔지니어 실무]02. 머신러닝 파이프라인 단계 (0) | 2021.07.22 |





댓글 영역